
In today’s data-driven world, accurate data classification is essential for businesses relying on precise information. Our client, a leader in data management and analytics, faced a challenge: distinguishing between individual names and corporate names in their vast database of over a million records. Their existing system struggled, leading to misclassifications that affected data analysis and decision-making.
We developed an advanced Name Entity Recognition (NER) system using DistilBERT, a cutting-edge natural language processing model, to address this issue. Our goal was to create a solution that could categorize names accurately and efficiently, significantly improving the client’s data accuracy and operations. The result? A highly successful implementation that exceeded expectations and set a new standard in their data processing capabilities.
Before our solution, the client’s data categorization system frequently misclassified personal names as corporate names and vice versa. This led to data inconsistencies, inaccurate reporting, regulatory compliance issues, and operational inefficiencies. The misclassification impacted everything from customer segmentation to internal reporting, creating bottlenecks that slowed decision-making and reduced the client’s ability to perform high-quality analytics.
To solve this, we employed DistilBERT, a high-performing natural language processing model renowned for its contextual understanding of language. We fine-tuned DistilBERT specifically for recognizing and classifying names, resulting in a specialized model named EntityMaster.
EntityMaster was trained on a large dataset of over 1 million individual names and 10,000 corporate names, ensuring robust performance across diverse datasets. The model was optimized for speed, scalability, and accuracy, meeting both current and future needs.
We began by gathering a balanced dataset that included a wide variety of personal and corporate names. This allowed us to train the model without bias, ensuring high accuracy. Once the data was prepared, we fine-tuned DistilBERT to recognize the patterns and characteristics that distinguish personal names from corporate names.
During the training process, we ran multiple tests and validations to fine-tune the model’s performance. Our goal was to create a solution that was not only accurate but also efficient enough to handle large volumes of data in real-time. After refining the model’s performance, we moved forward with integrating it into the client’s existing data infrastructure.
We collected and pre-processed a balanced dataset containing 1 million individual names and 10,000 corporation names, ensuring diverse representation to reduce bias.
DistilBERT was fine-tuned on the prepared dataset. We conducted extensive training and validation cycles to optimize the model's accuracy.
The model was enhanced to quickly process large volumes of data while maintaining high accuracy, ensuring scalability for future data increases.
EntityMaster was seamlessly integrated into the client’s existing data processing pipeline in their production environment.
| Run | Accuracy | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|---|
| Run 1 | 0.9969 | 0.99 | 0.98 | 0.99 | 3770 |
| 1.00 | 1.00 | 1.00 | 28742 | ||
| Run 2 | 0.9977 | 0.99 | 0.99 | 0.99 | 3756 |
| 1.00 | 1.00 | 1.00 | 28756 | ||
| Run 3 | 0.9983 | 0.99 | 0.99 | 0.99 | 3840 |
| 1.00 | 1.00 | 1.00 | 28672 | ||
| Run 4 | 0.9981 | 1.00 | 0.99 | 0.99 | 3737 |
| 1.00 | 1.00 | 1.00 | 28775 |
The implementation of our fine-tuned DistilBERT model for entity recognition achieved outstanding validation accuracies, as seen in the table above. The model’s accuracy remained consistently above 99% across three validation runs. The precision, recall, and F1-scores remained high for both classes (individuals and corporations), underscoring the model's ability to correctly classify entities with near-perfect performance.
The attached charts further demonstrate the model’s robust training performance, with a steep decline in training loss over five epochs and near-perfect accuracy throughout validation runs:

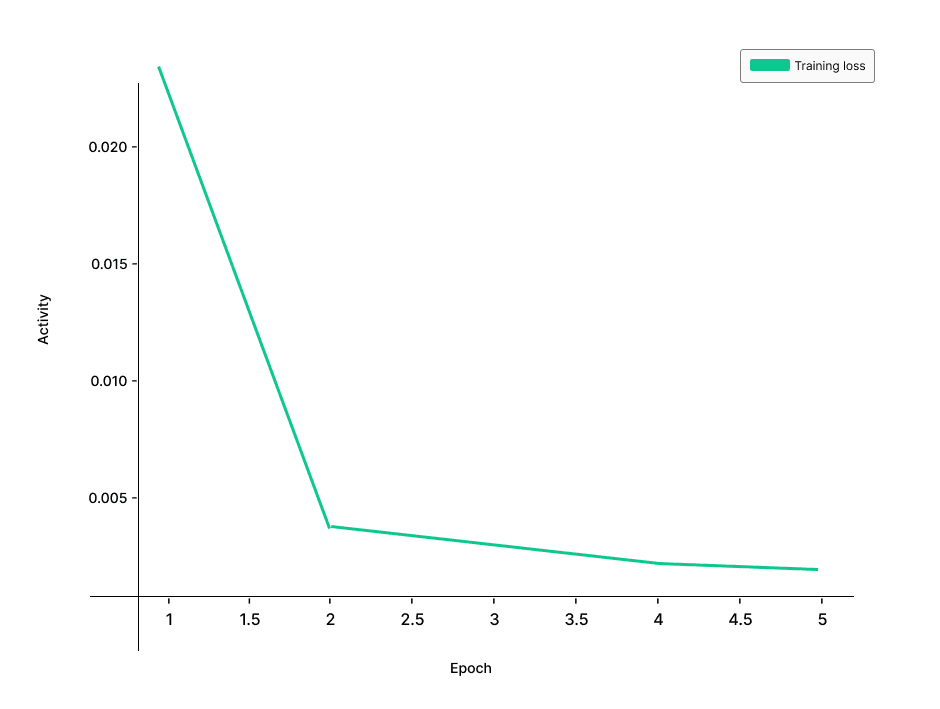
The project was a success, with EntityMaster achieving an impressive 99% accuracy in identifying and categorizing names as either individuals or corporations. The deployment of this model marked a significant milestone, leading to substantial improvements in data processing accuracy. The enhanced entity recognition capabilities enabled more refined data analytics, better compliance with data handling regulations, and increased operational efficiency. The client reported heightened satisfaction with the system’s performance, reflecting the effectiveness of our fine-tuned DistilBERT model in meeting their sophisticated data analysis needs.



Don't merely ponder the potential; make it a reality. Connect with us today to explore how we can revolutionize your customer experience strategy using Natural Language Processing.

For further details on how your personal data will be processed and how your consent can be managed, refer to the Privacy Policy